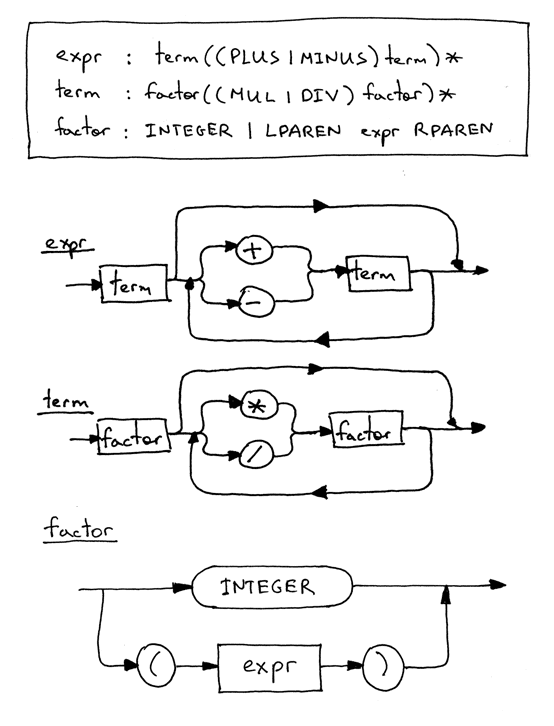
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| from typing import NamedTuple
import re
class Token(NamedTuple):
type: str
value: str
pos: int
def tokenize(line:str):
"""将字符串解析成tokens"""
if len(line.strip().splitlines()) > 1:
raise Exception('only parse one line')
line = line.strip()
SPECIFICATION = [
('NUMBER', r'\d+(\.\d*)?'),
('LP',r'\('),
('RP',r'\)'),
('OP1', r'[\+\-]'),
('OP2', r'[\*/]'),
('SKIP',r'[ \t]+'),
('MISMATCH',r'.'),
]
tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in SPECIFICATION)
for mo in re.finditer(tok_regex, line):
kind = mo.lastgroup
value = mo.group()
pos = mo.start()
if kind == 'MISMATCH':
raise Exception('mismatch: %s, position:%d' % (value, pos))
if kind != 'SKIP':
yield Token(kind, value, pos)
|